# 세줄요약 #
- 머신러닝은 데이터와 기댓값이 주어졌을 때 데이터처리 작업을 위한 실행규칙을 찾는 것으로 다시 말하면 입력데이터를 기반으로 기대출력에 가깝게 만드는 유용한 표현(Representation)을 학습하는 것이다(표현: 데이터를 해석하는 다른 방법).
- 딥러닝은 기본층을 겹겹이 쌓아올려 구성한 신경망(Neural Network)이라는 모델을 사용하여 의미있는 표현을 학습하는 것으로, 심층신경망을 정보가 연속된 필터를 통과하면서 순도높게 정제되는 다단계 정보 추출작업을 의미한다.
- 딥러닝이 다른 머신러닝 기법(Logistic Regression, SVM: Support Vector Machine 등등)보다 빠르게 확산된 이유는 데이터의 좋은 표현을 직접 찾는 특성공학(feature engineering) 단계가 자동화되어 고도의 다단계 작업을 하나의 End-to-End 딥러닝 모델로 대체할 수 있기 때문이다.
1. 인공지능과 머신러닝, 딥러닝
- 인공지능: 보통의 사람이 수행하는 지능적인 작업을 자동화하기 위한 연구 활동
- 머신러닝: 입력 데이터와 기댓값(해답 데이터)을 받아서 기대 출력에 가깝게 만드는 유용한 표현(representation)을 학습하는 것을 의미하며 인공지능을 만드는 방법 중 하나
- 딥러닝: 신경망(Neural Network)이라는 연속된 층에서 데이터로부터 점진적으로 의미있는 표현을 학습하는 새로운 머신러닝 기법 중 하나

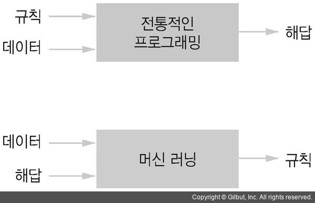

2. 머신러닝의 간략한 역사
- 확률적 모델링(Probabilistic Modeling): 통계학 이론을 데이터 분석에 응용한 것으로 초창기 머신러닝 형태 중의 하나. 잘 알려진 알고리즘으로는 Naive Bayes, Logistic Regression 등이 있다.
- 초창기 신경망: 신경망의 핵심 아이디어 자체는 1950년대부터 연구되었으나, 대규모 신경망을 학습시키는 문제를 해결하지 못하여 발전이 없다가 1980년대 들어서야 다양한 역전파 알고리즘들이 개발되면서 본격적으로 시작. 성공적인 첫번째 신경망은 1989년 벨 연구소(Bell Labs)의 얀 르쿤(Yann LeCun)이 개발한 LeNet.
- 커널 방법(Kernal Method): 분류 알고리즘의 한 종류이며 가장 유명한 알고리즘은 서포트 벡터 머신(Support Vector Machine; SVM)이다.
- SVM 알고리즘: 먼저 주어진 데이터 분포에서 데이터를 나눌 수 있는 새로운 고차원의 결정 경계인 초평면(hyperplane)에서 데이터를 매핑하고(2차원 데이터의 경우 그보다 고차원인 1차원의 직선이 초평면), 초평면과 각 클래스의 가장 가까운 데이터들의 거리(Margin)가 최대가 되도록 결정 경계(초평면)을 찾는다.

- 결정트리(decision tree): 플로차트(flowchart) 같은 구조를 가지며 입력 데이터 포인트를 분류하거나 주어진 입력에 대해 출력값을 예측.
- 랜덤 포레스트(Random Forest): 결정트리에 기초한 알고리즘으로 서로 다른 결정 트리를 많이 만들어서 그 출력을 앙상블 하는 방법.
- 그래디언트 부스팅 머신(gradient boosting machine): 결정트리를 앙상블하는 것을 기반으로 한뒤, 이전 모델에서 놓친 데이터 포인트를 보완하는 새로운 모델을 반복적으로 훈련함으로서 머신러닝모델을 향상시키는 그래디언트 부스팅 기법을 적용한 알고리즘.

- 신경망의 대두: 2012년 ImageNet(대규모 이미지 분류 대회)에서 토론토 대학의 제프리 힌튼(Geoffrey Hinton)이 지도하는 Alex Krizhevsky 팀이 딥러닝을 사용하여 우승한 이후 매년 신경망을 사용한 팀이 우승을 하였고, 2015년 딥러닝을 사용한 우승자가 96.4%의 정확도를 달성함으로서 ImageNet 분류 문제는 완결된 것으로 간주되었다.
3. 딥러닝이 떠오른 이유
- 하드웨어: 비디오 게임에서 쓰이던 대용량 고속 병렬 칩(GPU; 그래픽 처리 장치)의 발전
- 데이터: 저장 장치의 급격한 발전과 대량의 데이터셋을 수집하고 배포할 수 있는 인터넷의 성장이 머신러닝의 연료라 할 수 있는 데이터를 대량으로 생산하고 효율적으로 모을 수 있게 함.
- 알고리즘: 깊은 심층 신경망을 안정적으로 훈련시킬 수 있는 여러 알고리즘이 개발되고 향상.
- 신경망의 층에 더 잘 맞는 활성화 함수(Activation Function)
- 층별 사전 훈련(pretraining)을 불필요하게 만든 가중치 초기화(weight initialization) 방법
- RMSProp과 Adam과 같은 더 좋은 최적화 방법
* 출처: 케라스 창시자에게 배우는 딥러닝 / 프랑소와 숄레 / 길벗

728x90
728x90
'교재 리뷰 > 케라스 창시자에게 배우는 딥러닝' 카테고리의 다른 글
| 케라스 창시자에게 배우는 딥러닝 - 5. 컴퓨터 비전을 위한 딥러닝 (0) | 2020.11.16 |
|---|---|
| 케라스 창시자에게 배우는 딥러닝 - 4. 머신 러닝의 기본 요소 (0) | 2020.10.20 |
| 케라스 창시자에게 배우는 딥러닝 - 3. 신경망 시작하기 (3) | 2020.08.31 |
| 케라스 창시자에게 배우는 딥러닝 - 2. 시작하기 전에: 신경망의 수학적 구성 요소 (1) | 2020.08.18 |
| 케라스 창시자에게 배우는 딥러닝 - 개요 (1) | 2019.12.04 |




댓글