# 세줄요약 #
- 텍스트를 다루려면 텍스트를 단어, 문자, n-그램 단위로 나눠주는 토큰화(tokenization)라는 작업을 해주어야 하며, 이러한 토큰화에는 단순히 0, 1을 이용하여 행렬 배치해주는 '원핫 인코딩(one-hot encoding)'과 학습을 통해 단어 벡터(word vector)로 만들어주는 '단어 임베딩(word embedding)' 두가지 방법이 존재한다.
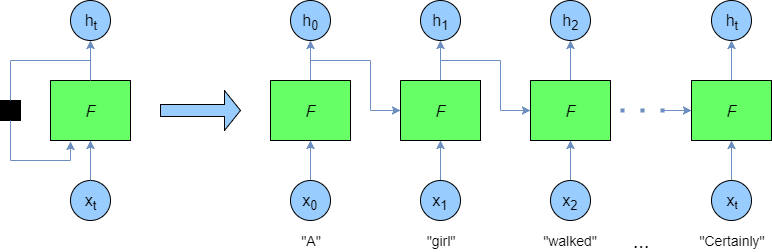
- 시퀀스 또는 시계열 데이터인 자연어 처리를 위해서는 네트워크가 전체 시퀀스의 흐름을 분석할 필요가 있고, 따라서 시퀀스의 원소를 순회하며 처리한 상태를 저장하고, 이전의 처리한 정보를 재사용하는 순환신경망(RNN: Recurrent Neural Network)이 주로 사용된다.
- 순환신경망(RNN)에서 주로 쓰이는 층(layer)로는 LSTM(Long Short Term Memory, 장단기 메모리 알고리즘)층과 GRU(Gated Recurrent Unit)층이 있으며, 추가로 순환신경망의 성능을 향상시키는 방법에는 순환 드롭아웃, 스태킹 순환 층, 양방향 순환 층 등이 존재한다.
# 상세 리뷰 #
1. 텍스트를 다루려면 텍스트를 단어, 문자, n-그램 단위로 나눠주는 토큰화(tokenization)라는 작업을 해주어야 하며, 이러한 토큰화에는 단순히 0, 1을 이용하여 행렬 배치해주는 '원핫 인코딩(one-hot encoding)'과 학습을 통해 단어 벡터(word vector)로 만들어주는 '단어 임베딩(word embedding)' 두가지 방법이 존재한다.
- 토큰화(tokenization)
- 텍스트를 토큰으로 나누는 작업
- 토큰(token): 텍스트를 나누는 단위
- 단어, 문자, n-gram(연속된 단어나 문자의 그룹)

- 텍스트의 원핫 인코딩(one-hot encoding)
- 토큰을 벡터로 변환하는 가장 일반적이고 기본적인 방법
- 모든 단어에 고유한 정수 인덱스를 부여하고 이 정수 인덱스 i를 크기가 N(어휘 사전의 크기)인 이진 벡터로 변환(i번째 원소만 1이고 나머지는 모두 0)
- 단어 임베딩(word embedding)
- 토큰화 시킨 텍스트(단어)를 기하학적인 파라미터 공간에 데이터 학습을 통해 매핑하는 것
- 원핫 인코딩과 달리 적은 차원에 벡터를 밀집 시킬 수 있다.
- 단어 임베딩을 만드는 방법
- 관심 대상인 문제와 함께 단어 임베딩을 학습
- 사전 훈련된 단어 임베딩(pretrained word embedding)을 활용 (* 추천: Word2vec, GloVe)

2. 시퀀스 또는 시계열 데이터인 자연어 처리를 위해서는 네트워크가 전체 시퀀스의 흐름을 분석할 필요가 있고, 따라서 시퀀스의 원소를 순회하며 처리한 상태를 저장하고, 이전의 처리한 정보를 재사용하는 순환신경망(RNN: Recurrent Neural Network)이 주로 사용된다.
- 순환 신경망
- 일반적인 DNN(Deep Neural Network)이나 CNN(Convolutional Neural Network)의 경우 메모리의 개념이 없기 때문에, 이런 신경망으로는 시퀀스나 시계열 데이터 포인트를 처리하려면 전체 시퀀스를 학습시켜야 한다.
- 순환신경망은 시퀀스의 원소를 순회하면서 지금까지 처리한 정보를 상태(state)에 저장하여 학습이 반복될 때 이전에 계산한 정보를 재사용하는 알고리즘이다.
- output_t = activation(np.dot(W, input_t) + np.dot(U, state_t) +b)
- input_t: 2D 텐서 = (timesteps, input_features)
- state_t: 2D 텐서 = (timesteps-1, input_features-1) <- 이전 타임스텝에서의 출력 저장값
- W, U: 가중치, b: 편향벡터(bias)
- output_t: 2D 텐서 = (timesteps, output_features)
3. 순환신경망(RNN)에서 주로 쓰이는 층(layer)로는 LSTM(Long Short Term Memory, 장단기 메모리 알고리즘)층과 GRU(Gated Recurrent Unit)층이 있으며, 추가로 순환신경망의 성능을 향상시키는 방법에는 순환 드롭아웃, 스태킹 순환층, 양방향 순환층 등이 존재한다.
- LSTM(Long Short Term Memory)
- 위에서 설명한 단순한 순환신경망(SimpleRNN)은 이론적으로 시간 t에서 이전의 모든 타임스텝의 정보를 유지할 수 있지만, 시간이 길어지면 모든 DNN에서 흔히 일어나는 Vanishing Gradient(그래디언트 소실) 문제로 인해 긴 시간에 걸친 의존성은 학습할 수 없다.
- 장단기 메모리(Long Short Term Memory, LSTM) 알고리즘: Vanishing Gradient 문제를 해결하기 위해 정보를 여러 타임스텝에 걸쳐 나르는 방법이 추가
- 시퀀스 어느 지점에서 추출된 정보가 이동트랙을 따라가다가 필요한 시점의 타임스텝에서 입력으로 주입된다.
- 나중을 위해 정보를 저장함으로써 처리 과정에서 오래된 시그널이 점차 소실되는 것을 방지한다.
- 즉, SimpleRNN과 가장 구별되는 특징은 타임스텝을 가로질러 정보를 나르는 데이터 흐름이 추가된다는 것이다. 이때 타임스텝 t에서의 이동상태를 c_t라고 하면, 다음 이동상태(c_t+1)를 구하는 식은 다음과 같다.
output_t = activation(c_t) * activation(dot(input_t, Wo) + dot(state_t, Uo) + bo)
i_t = activation(dot(state_t, Ui) + dot(input_t, Wi) + bi)
f_t = activation(dot(state_t, Uf) + dot(input_t, Wf) + bf)
k_t = activation(dot(state_t, Uk) + dot(input_t, Wk) + bk)
c_t+1 = i_t * k_t + c_t * f_t
# c_t * f_t: 데이터 흐름에서 관련이 적은 정보를 의도적으로 삭제
# i_t, k_t: 현재에 대한 정보를 제공하고 이동 트랙을 새로운 정보로 업데이트
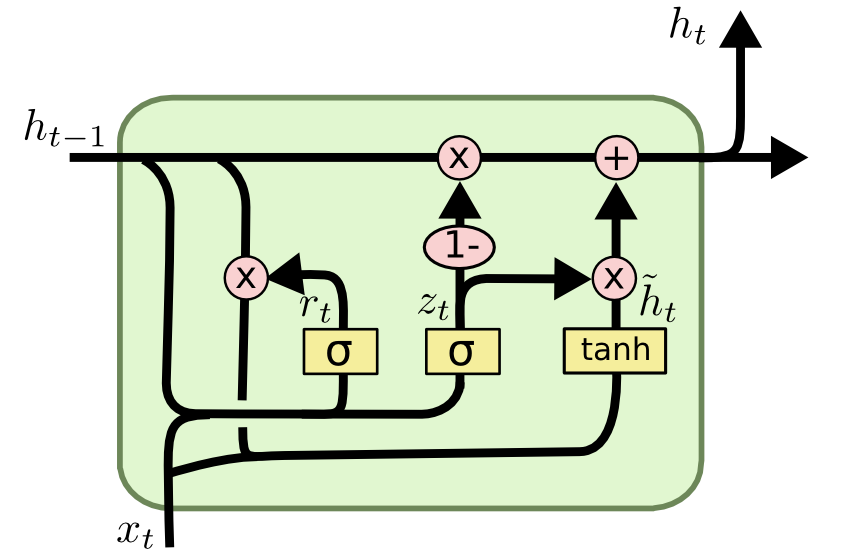
- GRU(Gated Recurrent Unit)
- LSTM과 같은 원리로 작동하지만 조금 더 간결하고, 계산비용이 적다. 그렇지만 학습 능력은 조금 떨어짐.
- 순환 신경망의 고급 사용법
- 순환 드롭아웃(recurrent dropout): 순환 층에서 과대적합을 방지하기 위해 케라스에 내장되어 있는 드롭아웃 사용
- 기존의 일반적인 DNN에서의 드롭아웃과 달리 타임스텝마다 드롭아웃 패턴이 바뀌는 것이 아니라, 동일한 드롭아웃 패턴이 모든 타임스텝에 적용되어야 함
- 스태킹 순환층(stacking recurrent layer): 네트워크의 표현능력을 증가, 그 대신 계산 비용도 증가함
- 네트워크의 용량을 늘리기 위해 층에 있는 유닛의 수를 늘리거나 층을 더 많이 쌓는 것(stacking)
- 순환 층을 쌓을 때는 모든 중간층의 마지막 타임스텝만이 아닌 전체 시퀀스(3D텐서)를 출력해야함
- 양방향 순환층(bidirectional recurrent layer): 순환 네트워크에 같은 정보를 다른 방향으로 주입
- RNN의 입력 순서를 시간 순서 한방향만 넣는 것 아니라 시간 반대 순서도 함께 넣어서 처리한다.
- 순환 드롭아웃(recurrent dropout): 순환 층에서 과대적합을 방지하기 위해 케라스에 내장되어 있는 드롭아웃 사용
* 출처: 케라스 창시자에게 배우는 딥러닝 / 프랑소와 숄레 / 길벗

'교재 리뷰 > 케라스 창시자에게 배우는 딥러닝' 카테고리의 다른 글
| 케라스 창시자에게 배우는 딥러닝 - 7. 딥러닝을 위한 고급 도구 (0) | 2020.12.08 |
|---|---|
| 케라스 창시자에게 배우는 딥러닝 - 5. 컴퓨터 비전을 위한 딥러닝 (0) | 2020.11.16 |
| 케라스 창시자에게 배우는 딥러닝 - 4. 머신 러닝의 기본 요소 (0) | 2020.10.20 |
| 케라스 창시자에게 배우는 딥러닝 - 3. 신경망 시작하기 (3) | 2020.08.31 |
| 케라스 창시자에게 배우는 딥러닝 - 2. 시작하기 전에: 신경망의 수학적 구성 요소 (0) | 2020.08.18 |




댓글