# 세줄 요약 #
- 다중 입력, 다중 출력, 복잡한 네트워크 topology를 갖는 모델의 경우 케라스에서는 함수형API를 사용하며, Input layer와 output layer들을 정의한 후 마지막에 'Model([input_1, input_2], [output_1, output_2, output3])'과 같은 함수의 형태로 묶어줘야 한다.
- 케라스 콜백(callback)은 모델의 fit() 메서드가 호출될 떄 전달되는 객체로서 모델 체크포인트 저장, 조기 종료(early stopping), 하이퍼 파라미터 동적 조정(ex. Learning rate), 텐서보드 시각화 등이 있다.
- 딥러닝 모델의 성능을 최대한으로 끌어올리는 방법에는 Batch Normalization, Separable Convolution 등과 같은 고급 구조 패턴을 사용하거나 다양한 하이퍼 파라미터 최적화 기법(bayesian optimization, genetic algorithm, random search), 모델 앙상블(model ensemble) 등이 있다.
# 상세 리뷰 #
1. 다중 입력, 다중 출력, 복잡한 네트워크 topology를 갖는 모델의 경우 케라스에서는 함수형API를 사용하며, Input layer와 output layer들을 정의한 후 마지막에 'Model([input_1, input_2], [output_1, output_2, output3])'과 같은 함수의 형태로 묶어줘야 한다.
- 함수형 API(functional API): 함수처럼 층을 사용하여 직접 텐서들의 입력을 받고 출력한다.
- 함수 형태로 모든 레이어를 정의한 후에 마지막에 최종적으로 input_tensor와 output_tensor만 Model(input_tensor, output_tensor) 클래스로 묶어주면 신경망 모델이 만들어진다.
"""
Sequential 모델과 함수형 API로 동일한 모델 코드 비교
"""
from keras.models import Sequential, Model
from kears import layers, Input
# Sequential Model
seq_model.add(layers.Dense(32, activation='relu', input_shape=(64,)))
seq_model.add(layers.Dense(32, activation='relu'))
seq_model.add(layers.Dense(10, activation='softmax')
# 함수형 API
input_tensor = Input(shape=(64,))
x = layers.Dense(32, activation='relu')(input_tensor)
x = layers.Dense(32, activation='relu')(x)
output_tensor = layers.Dense(10, activation='softmax')(x)
- 다중 입력 모델
from keras.models import Model
from keras import layers
from keras import Input
text_vocabulary_size = 10000
question_vocabulary_size = 10000
answer_vocabulary_size = 500
text_input = Input(shape=(None,), dtype='int32', name='text') # input_1: 참고 문장
embedded_text = layers.Embedding(text_vocabulary_size, 64)(text_input)
encoded_text = layers.LSTM(32)(embedded_text)
question_input = Input(shape=(None,), dtype='int32', name='question') # input_2: 질문
embedded_question = layers.Embedding(question_vocabulary_size, 32)(question_input)
encoded_question = layers.LSTM(16)(embedded_question)
concatenated = layers.concatenate([encoded_text, encoded_question], axis=-1) # input 2개 연결
answer = layers.Dense(answer_vocabulary_size, activation='softmax')(concatenated) # output: 응답
model = Model([text_input, question_input], answer) # 두개의 입력 주입
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc'])
- 다중 출력 모델
from keras import layers
from keras import Input
from keras.models import Model
vocabulary_size = 50000
num_income_groups = 10
post_input = Input(shape=(None,), dtype='int32', name='posts') # input: 소셜 미디어 사용자 포스트
embedded_posts = layers.Embedding(volcabulary_size, 256)(post_input)
x = layers.Conv1D(128, 5, activation='relu')(embedded_posts)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.GlobalMaxPooling1D(5)(x)
x = layers.Dense(128, activation='relu')(x)
age_prediction = layers.Dense(1, name='age')(x) # output_1: 나이 예측
income_prediction = layers.Dense(num_income_groups, activation='softmax', name='income')(x) # output_2: 수입 예측
gender_prediction = layers.Dense(1, activation='sigmoid', name='gender')(x) # output_3: 성별 예측
model = Model(posts_input, [age_prediction, income_prediction, gender_prediction])
model = compile(optimizer='rmsprop', loss={'age': 'mse', 'income': 'categorical_crossentropy', 'gender': 'binary_crossentropy'})
# 출력이 3개이므로 각각에 대해서 loss function을 설정해주어야함
2. 케라스 콜백(callback)은 모델의 fit() 메서드가 호출될 떄 전달되는 객체로서 모델 체크포인트 저장, 조기 종료(early stopping), 하이퍼 파라미터 동적 조정(ex. Learning rate), 텐서보드 시각화 등이 있다.
- 모델 체크포인트 저장: 훈련하는 동안 어떤 지점에서 모델의 현재 가중치를 저장
- 조기 종료(early stopping): 검증 손실(또는 정확도, Dice score 등등)이 더이상 향상되지 않을 때 훈련을 중지
- 하이퍼 파라미터 동적 조정: 옵티마이저(optimizaer)의 학습률(Learning rate) 등의 하이퍼 파라미터 값이 훈련 도중 동적으로 조정(* 예: 10 epoch 동안 성능이 향상되지 않을 시 학습률 1/10으로 감소).
- 텐서보드 시각화: 텐서보드를 통해 학습 진행 상황을 확인하거나 사실 터미널에서 보이는 케라스의 진행 표시줄(progress bar) 또한 하나의 콜백이다.
"""
케라스 콜백 예시
"""
callback_list = [keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=20, mode='max'),
keras.callbacks.ModelCheckpoint(filepath='save_path/model.h5', monitor='val_accuracy', save_best_only=True, mode='max'),
keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=10, mode='min'),
keras.callbacks.TensorBoard(log_dir=log_save_path, histogram_freq=1, embeddings_freq=1)]
# EarlyStopping: 검증 정확도(val_accuracy) 기준으로 20 에폭동안 성능이 상승(max)하지 않으면 조기 종료
# ModelCheckpoint: 검증 정확도(val_accuracy) 기준으로 가장 성능이 좋은 모델만 저장(save_best_only=True)
# ReduceLROnPlateau: 검증 손실(val_loss) 기준으로 10 에폭동안 손실이 감소(min)하지 않으면 학습률을 10분의 1로 감소(factor=0.1)
# TensorBoard: 텐서보드 시각화 1 에폭마다 히스토그램과 임베딩 데이터 기록
model.fit(x, y, epochs=10, batch_size=32, callbacks=callbacks_list)
3. 딥러닝 모델의 성능을 최대한으로 끌어올리는 방법에는 Batch Normalization, Separable Convolution 등과 같은 고급 구조 패턴을 사용하거나 다양한 하이퍼 파라미터 최적화 기법(bayesian optimization, genetic algorithm, random search), 모델 앙상블(model ensemble) 등이 있다.
- 고급 구조 패턴
- Batch Normalization: 데이터를 모델에 주입하기 해주었던 정규화를 네트워크에서 훈련되는 동안에도 층과 층 사이에서 바뀌는 평균과 분산을 정규화해주는 레이어
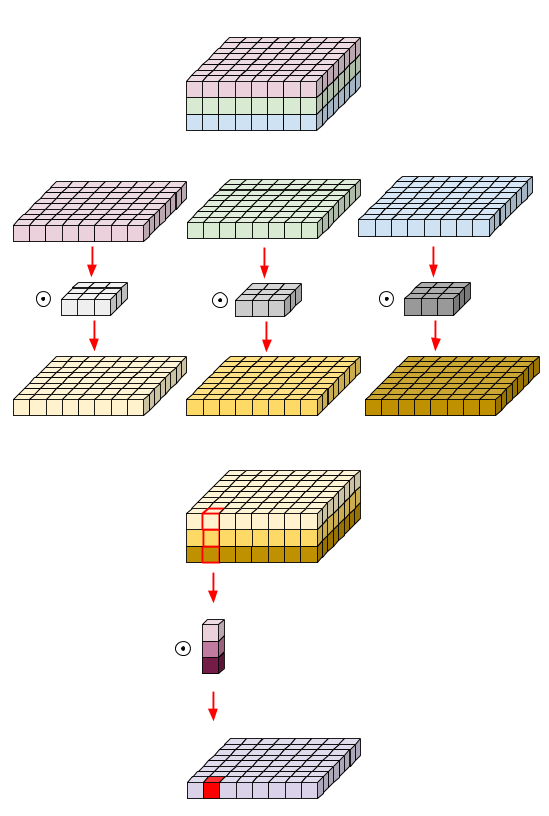
- Separable Convolution: 깊이별 분리 합성곱 - depthwise separable convolution
- 입력 채널별로 따로따로 공간 방향의 합성곱을 수행한 뒤에 점별 합성곱(1x1 Convolution)을 통해 출력 채널을 합침
- 입력에서 공간상 위체는 상관관계가 크지만 채널별로는 독립적이라고 가정한다면 이는 공간 특성의 학습과 채널방향 특성을 분리하여 적은 데이터로도 더 효율적인 학습이 가능하게 한다.
- 하이퍼 파라미터 최적화
- 일반적으로 머신러닝, 딥러닝 엔지니어들이 가장 시간을 많이 쏟는 일은 하이퍼 파라미터를 수정해가며 성능을 올리는 하이퍼 파라미터 튜닝 과정이다.
- 이러한 하이퍼 파라미터 튜닝 과정을 자동화시키는 여러 알고리즘들이 존재한다.
- 베이지안 최적화(bayesian optimization)
- 유전 알고리즘(genetic algorithm)
- 랜덤 탐색(random search)
- 모델 앙상블
- 여러 개의 다른 모델의 예측을 합쳐서 더 좋은 예측을 만드는 기법
- K-fold Cross Validation에서 각 fold 별로 얻은 예측을 합치는 과정도 앙상블이다.
"""
모델 앙상블
"""
preds_a = model_a.predict(x_val)
preds_b = model_b.predict(x_val)
preds_c = model_c.predict(x_val)
preds_d = model_d.predict(x_val)
final_preds = 0.25 * (preds_a + preds_b + preds_c + preds_d)
# 분류기마다 성능이 다를 경우 가중치 조정
final_preds = 0.5 * preds_a + 0.25 * preds_b + 0.1 * preds_c + 0.15 * preds_d
* 출처: 케라스 창시자에게 배우는 딥러닝 / 프랑소와 숄레 / 길벗

'교재 리뷰 > 케라스 창시자에게 배우는 딥러닝' 카테고리의 다른 글
| 케라스 창시자에게 배우는 딥러닝 - 6. 텍스트와 시퀀스를 위한 딥러닝 (0) | 2020.12.03 |
|---|---|
| 케라스 창시자에게 배우는 딥러닝 - 5. 컴퓨터 비전을 위한 딥러닝 (0) | 2020.11.16 |
| 케라스 창시자에게 배우는 딥러닝 - 4. 머신 러닝의 기본 요소 (0) | 2020.10.20 |
| 케라스 창시자에게 배우는 딥러닝 - 3. 신경망 시작하기 (3) | 2020.08.31 |
| 케라스 창시자에게 배우는 딥러닝 - 2. 시작하기 전에: 신경망의 수학적 구성 요소 (0) | 2020.08.18 |




댓글