# 세줄요약 #
- 'Inception'이라고 불리는 새로운 모듈로 구성한 Deep CNN(Convolutional Neural Network), 일명 'GoogLeNet' 을 처음으로 소개한 논문으로, GoogleNet은 ILSVRC14(ImageNet Large-Scale Visual Recoginition Challenge 2014)에서 Classification과 Detection 모두에서 최고의 성능을 보였다.
- Inception 모듈은 multi-scale processing과 Hebbian principle에서 영감을 얻어 이전 층의 특성지도(feature map)를 다양한 크기의 필터(1x1, 3x3, 5x5, pooling)로 병렬처리한 이후 다시 하나의 출력으로 합치는 구조를 가지고 있다.
- 이러한 Inception 모듈의 특징은 신경망의 깊이(depth)와 크기(width)를 늘리면서도 컴퓨터의 연산량(Computational budget)는 변하지 않는 것이 큰 장점이다.
# 상세 리뷰 #
1. 'Inception'이라고 불리는 새로운 모듈로 구성한 Deep CNN(Convolutional Neural Network), 일명 'GoogLeNet' 을 처음으로 소개한 논문으로, GoogleNet은 ILSVRC14(ImageNet Large-Scale Visual Recoginition Challenge 2014)에서 Classification과 Detection 모두에서 최고의 성능을 보였다.
- 한가지 재미있는 점은 GoogleNet이 아니라 GoogLeNet이다. (대문자 주의)
[Introduction]
- 논문이 발표된 2015년 기준으로 지난 3년간 영상 분류(Classification)와 물체 포착(Detection) 문제에 있어서 Convolutional Network를 사용한 딥러닝 기법이 우수한 성능을 보여 왔다.
- 더 우수한 네트워크를 만드는 방법
- 레이어(layer)가 더 깊고(Network depth), 필터(filter or node)가 더 많아서 넓은(Network width) 큰 네트워크를 만드는 것
- 그러나 단순히 네트워크의 층과 필터를 늘렸을 때 생기는 단점
- 오버피팅이 생긴다(네트워크의 수용력(Capacity)이 갑자기 커져서 지나치게 많은 특성들을 추출하기 때문).
- 컴퓨터 리소스가 많이 필요하다(Network가 더 깊고 넓어진다는 것은 계산량이 많아지는 것을 의미).
- 기존의 해결책
- Sparse한 큰 네트워크를 만든다.
- 이는 커다란 네트워크를 만들고 전체적으로 dropout 하는 것을 의미한다.
- 그러나 sparse 한 네트워크를 만들어도 근본적으로 커다란 네트워크이기에 파라미터 수가 많아서 계산할 값이 많아져 컴퓨터 리소스를 많이 차지하는 문제는 해결할 수 없다.
- 헤비안 이론(Hebbian principle)
- 도널드 헤브(Donald Hebb 1904~1985)가 1949년에 정립한 이 이론은 인간의 두뇌가 학습하는 과정을 신경세포가 어떻게 받아들이는지를 설명하는 이론이다.
- 이 이론은 “동시에 활성화되는 신경세포들은 함께 연결된다”(cells that fire together, wire together)라는 유명한 말로 요약된다.
- 이는 말하자면 신경세포가 좀 더 활성화될 때, 뇌에서는 그 생각이 더욱 강해진다는 것이다. 이를 연상학습 또는 헤비안 학습이라고 한다.
- 한 번 어떤 생각에 고정되면 어떤 이야기도 고정된 생각의 틀에 맞추는 것과 비슷하다고 할 것이다.
- 헤비안 이론 출처: 기억은 열역학 법칙과 유사하다
2. Inception 모듈은 multi-scale processing과 Hebbian principle에서 영감을 얻어 이전 층의 특성지도(feature map)를 다양한 크기의 필터(1x1, 3x3, 5x5, pooling)로 병렬처리한 이후 다시 하나의 출력으로 합치는 구조를 가지고 있다.
[GoogLeNet Architecture]
- 인셉션 모듈이 나온 이유
- 로컬하게는 sparse 하게, 전역적으로는 dense하게 만들어 파라미터 계산량을 유지하면서 문제점 해결
- 인셉션 모듈의 형태
- 로컬하게 Sparse한 효과를 주기 위해 이전 층의 특성맵(feature map)을 1x1, 3x3, 5x5 convolution layer들에 추가로 3x3 max pooling도 함께 병렬 연산한 이후에 Concatenation layer로 합쳐준다.
- 이는 다양한 필터를 사용해서 봄으로 다양한 스케일로 영상을 보는 효과를 준다.
- 그러면서 직렬로 모두 층을 쌓아서 연결시키지 않고 병렬로 연결시켰기에 모듈 내부만 보면 Sparse한 구조를 가지게 된다.
- 1x1 convolution layer의 역할
- 일반적인 3x3, 5x5 convolution layer 를 거치고 지나치게 많아지는 필터 갯수를 줄여준다.
- 즉 네트워크 전체의 파라미터 계산량을 조절해준다.

- GoogleNet의 형태
- 위의 인셉션 모듈들을 쌓아서 이루어진 네트워크 형태를 가지고 있으며, 네트워크의 깊이가 22 layer로 깊으면서도 파라미터 수는 적어서 컴퓨터 리소스를 크게 쓰지 않는다.
- 아까 인셉션 모듈 내부는 Sparse하다고 했는데 반대로 전체 네트워크에서 인셉션 모듈 자체는 많이 쌓아서 깊게 만들었으므로 이것이 구글넷이 지역적으로는 Sparse하나 전역적으로는 Dense한 이유이다.
- 마지막으로 분류기는 Global Average Pooling(GAP) layer 와 클래스 1000개를 분류하기 위한 출력층인 dense layer로 구성되어있다.
- VGG 모델의 경우 Fully Connected(FP) layer를 분류기에 사용하였다.
- 위의 인셉션 모듈들을 쌓아서 이루어진 네트워크 형태를 가지고 있으며, 네트워크의 깊이가 22 layer로 깊으면서도 파라미터 수는 적어서 컴퓨터 리소스를 크게 쓰지 않는다.
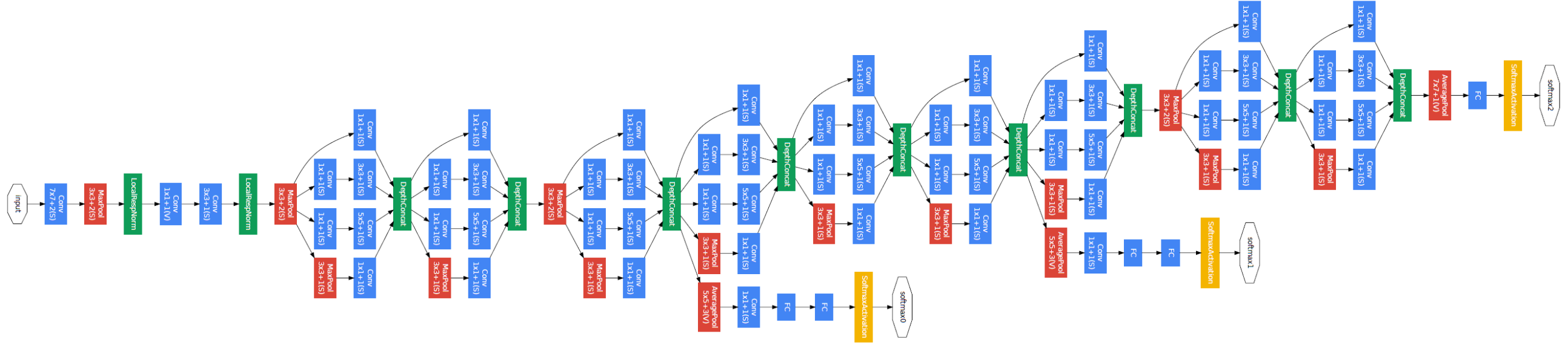
3. 이러한 Inception 모듈의 특징은 신경망의 깊이(depth)와 크기(width)를 늘리면서도 컴퓨터의 연산량(Computational budget)은 변하지 않는 것이 큰 장점이다.
[Experiment Result]
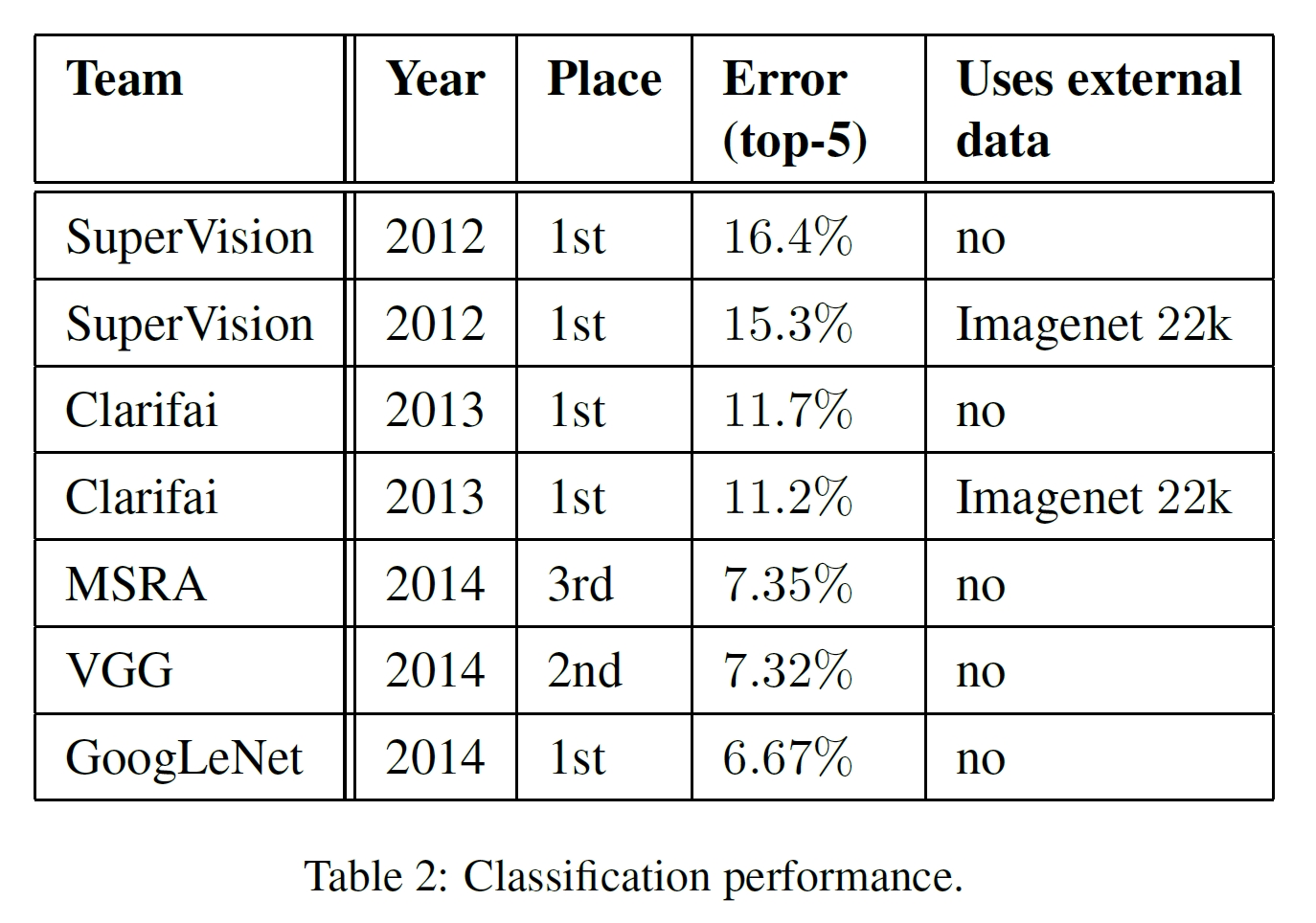
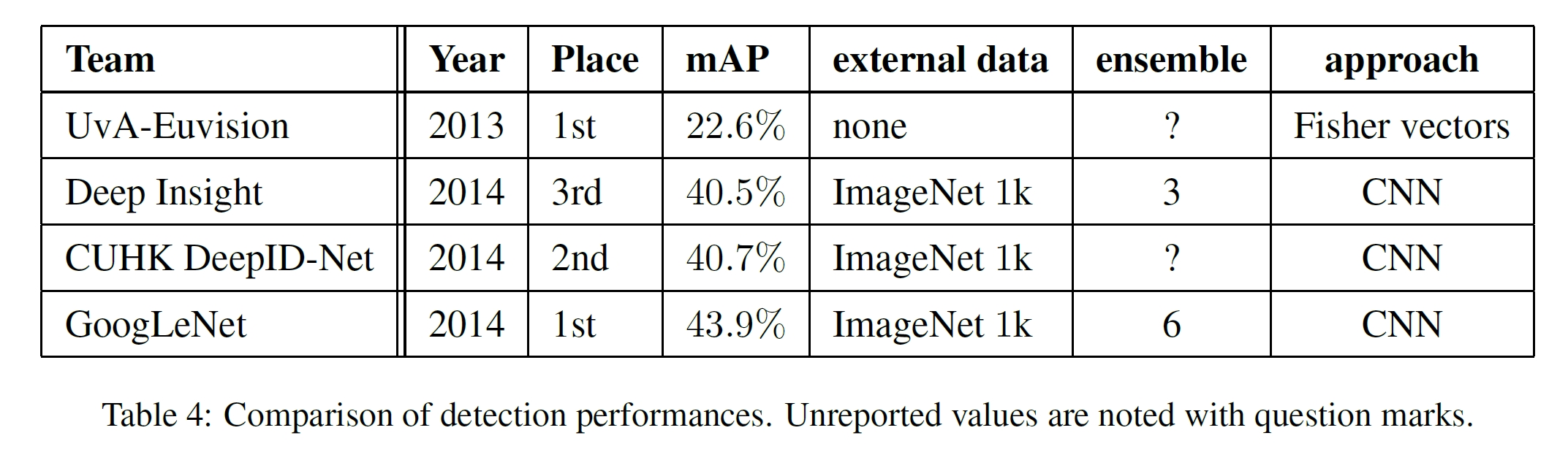
- 참가한 챌린지: ILSVRC 2014 challenge
- Classification과 Detection 모두 GoogLeNet이 가장 높은 성능으로 우승하였다.
- 데이터셋 구성
- train: 1.2 million images
- validation: 50,000 images
- test: 100,000 images
- 평가 성능
- Classification: test top-5 error
- Detection: mAP
* Reference:
Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
728x90
728x90




댓글